
The AI Health Race: What ChatGPT, Claude, and OpenEvidence Mean for Arizona Patients and Clinicians
By Anisia Corona, Brenda Mao, Jacqueline Vo, and Rohan Melwani
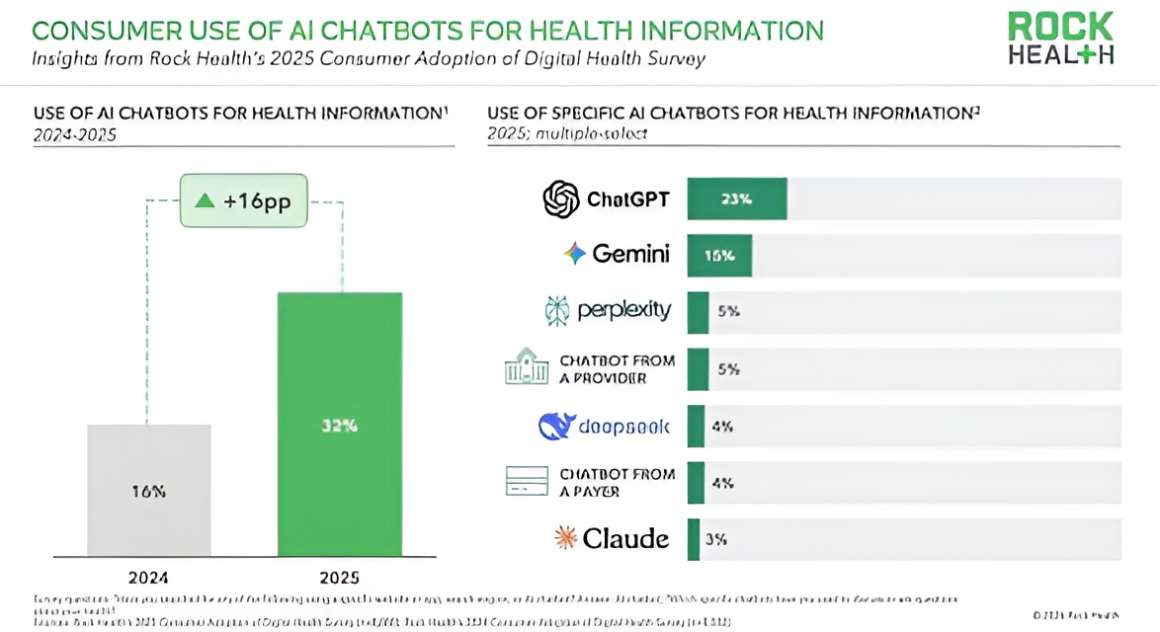
What if the AI tool you asked about your chest pain told you to wait 48 hours, when you were actually in the early stages of heart failure? That scenario is closer to reality than most patients realize. In a 2026 study published in Nature Medicine, leading AI systems gave unsafe guidance in a significant share of simulated emergency cases6.
At the same time, these tools are already moving into clinical environments. In Arizona, Banner Health has begun integrating models from Anthropic into its operations, signaling how quickly AI is shifting from experiment to infrastructure. This is the tension at the center of the AI health race. Large language models are now serving two very different roles: powering decision-making inside health systems, and guiding patients outside of them. Understanding how these systems differ, and where they succeed or fail, is becoming essential for both clinicians and the patients they serve.
According to Rock Health1, demand has been building for a health AI tool that is free or low-cost, and now purpose-built solutions have entered the market. Although the healthcare AI race includes companies such as Open AI, Anthropic, Open Evidence, Perplexity, Gemini, Microsoft, and Amazon, this article focuses on the first three because of their broad consumer adoption.
ChatGPT Health: First in Line, But With Caveats
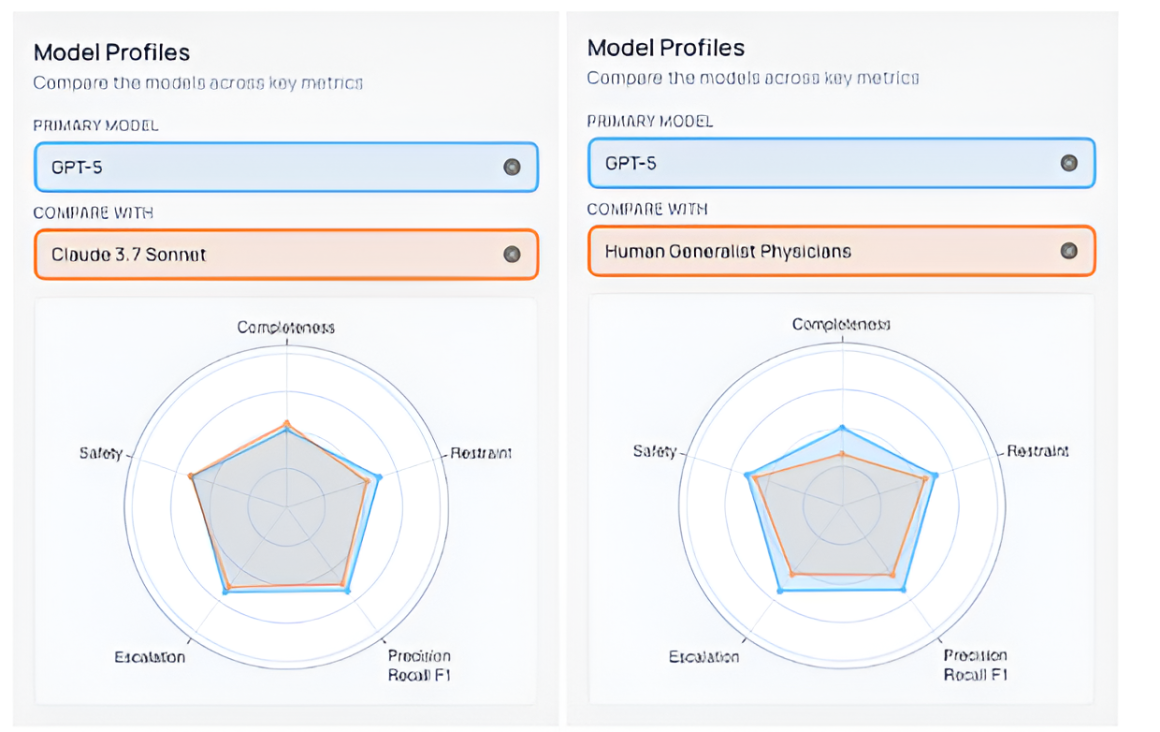
ChatGPT Health launched in January 2026 as OpenAI’s direct‑to‑consumer symptom checker and triage assistant, quickly attracting millions of users and positioning itself as a first‑line guide for deciding when and where to seek care. Through a partnership with b.well Connected Health, consumers can link longitudinal medical records from U.S. health systems, and also, data from apps such as Apple Health, MyFitnessPal, and others, giving the model a far richer view of medications, labs, vitals, and lifestyle patterns than most clinicians see in a 15‑minute visit2.
On the Medical AI Superintelligence Test (MAST), a benchmark developed by Harvard and Stanford to evaluate AI performance against trained physicians3, GPT‑5 ranks as the fourth‑best system with a 58.3% composite performance score, versus 46% for a human generalist physician3. Even the lighter, stripped-down versions of GPT-5 powering the free ChatGPT Health app outperform the average human generalist physician on standardized benchmarks, a fact that is either reassuring or unsettling, depending on how you look at it.
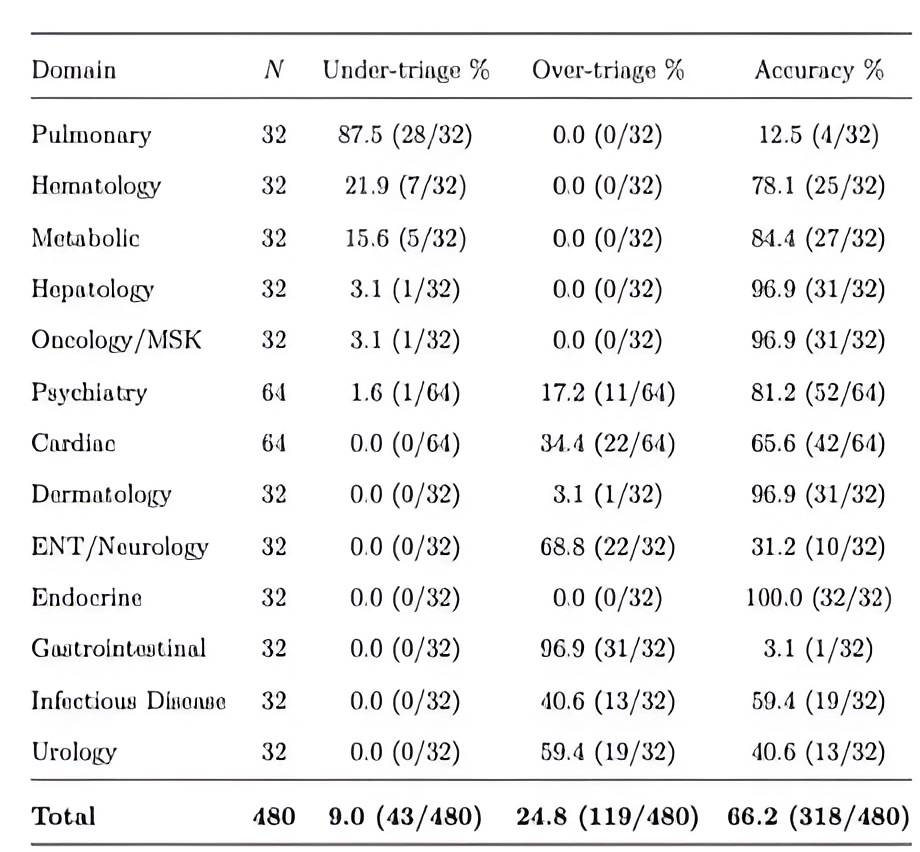
While this is promising, a Nature Medicine’s “crash test” using 60 clinician‑authored vignettes (960 total responses) found that ChatGPT Health under‑triaged 52% of gold‑standard emergencies, often steering patients with diabetic ketoacidosis or impending respiratory failure toward 24-48‑hour evaluation rather than the emergency department. Its most dangerous failures clustered at the extremes with nonurgent presentations incorrect in 35% of cases and emergency conditions at a worrying 48% incorrect. This means that in many severe cases that require immediate medical attention, ChatGPT Health underreacts, which can have severe health outcomes for users4.
These safety concerns are surfacing just as OpenAI faces a consumer‑trust shock. After its controversial Department of War (formerly DoD31) deal with the Pentagon, ChatGPT’s uninstall rate spiked 295% day‑over‑day and the service lost roughly 1.5 million paid subscribers, while Anthropic’s Claude saw day‑over‑day install growth up to 51% and Pro/Max subscriptions nearly double6. This distinction in subscription is critical because Claude for Healthcare is only available on those Pro/Max paid tiers.
Users, most of them hypersensitive to privacy, may be the first to move their most intimate data to the model they trust more, even as OpenAI races both to harden ChatGPT Health’s safety profile and, via its acquisition of OpenClaw, an agentic workflow startup, to build more agentic workflows that can act on patients’ behalf across records, scheduling, and benefits navigation7. With so many users jumping ship to Claude, social media influencers and Anthropic, the company that built Claude, quickly let users know how to transfer all their memory over to a new LLM8.
Claude for Healthcare: Enterprise Trust, Consumer Reach

Shortly following ChatGPT Health in early January 2026, Anthropic (Claude) released its new healthcare chatbot, Claude for Healthcare, powered by its latest model, Claude Sonnet 4.5. Although Claude is more focused on enterprise sales, it is also involved in the consumer side. Anthropic has integrated its model, Claude, with patients’ electronic health records (EHR) to assist patients with understanding their health data through personalized conversations in everyday language; HealthEx, Apple Health, and Android Health have all integrated their platforms with Claude9. Patients can directly ask questions, such as what this lab result means or how to interpret particular data.
Connectors, also called APIs, are the major component powering the business-to-business market appeal. They give AI chatbots, like Claude, direct access to other platforms’ industry-standard information and databases, such as the CMS, ICD-10, CDC, and the National Provider Identifier Registry. These enable easier and more reliable access to healthcare information that healthcare providers, payers, and health tech companies need. But real-world performance has not always matched the promise. For example, HealthScout Founder Joe Sipher said in a LinkedIn post10 on April 2, 2026, “Amazon’s announcement (about its newest Health AI inside the One Medical app) says it knows you and your medical history, but in my tests it didn’t know either.”
When tested using only Step 1 of the USMLE, Claude had a slightly lower accuracy than ChatGPT (95% and 100%, respectively), but provided the most comprehensive, anatomically-correct answers24. Finally, when tested with two Polish medical exams, the Medical-Dental Final Examination and Medical Final Examination, Claude achieved the highest overall accuracy for all question types compared to ChatGPT-4 and Gemini25. Although these results seem promising in regards to comprehensiveness, Step 2 and 3 tests of the USMLE cover what actually defines clinical competence and the skills that physicians use everyday. Until comparative Step 2 and 3 data is published, drawing conclusions about clinical readiness from Step 1 alone overstates what these tools can safely do.
Anthropic has earned a greater reputation compared to the other LLMs from several pharmaceutical companies, health systems, and startups, including AbbVie, Banner Health, and Stanford Healthcare11. Anthropic’s head of biology and life sciences, Eric Kauderer-Abrams, emphasizes a focus on enterprise customers rather than direct consumer health applications. In October 2025, Anthropic introduced Claude for Life Sciences, a version tailored for biopharma researchers and scientists. The company has since expanded it with integrations including Medidata, ClinicalTrials.gov, and the ToolUniverse library11. Top healthcare companies, such as Banner Health, Stanford Healthcare, and Novo Nordisk11, have put their trust in Claude, emphasizing the company’s leading approaches in AI safety and honesty.
OpenEvidence: Where Evidence-Based Medicine Meets AI
Unlike its counterparts, which rely on a single, publicly named model like GPT-5 or Claude, OpenEvidence is built on a proprietary, vertical LLM designed specifically for medicine13. Its model is trained on medical journals, clinical data, and curated medical content, made possible through formal partnerships with reputable, high-impact journals and publishers, such as the New England Journal of Medicine, JAMA Network, and the Wiley Online Library14. This specialization is what makes OpenEvidence promising in a B2B context, while many AI tools aim for broad adoption, OpenEvidence prioritizes verified clinicians as its most valuable customers.
OpenEvidence is “free and unlimited” for verified healthcare practitioners, including physicians, nurses, and frontline clinicians. The company’s revenue comes from enterprise relationships and advertising, not individual subscriptions. Backed by corporations such as Mayo Clinic, Nvidia, Sequoia, and Google Ventures, OpenEvidence is valued at $12 billion as of January 202615. OpenEvidence has also built an in-platform marketplace for pharmaceutical and medical advertising, which allowed the company to accrue over $100 million in annual revenue16. Dr. Yazan Al-Hasan, a neurologist at IYA Medical in Scottsdale said in an interview, “I don’t really pay attention to the ads.” Despite only being officially launched in 2023, OpenEvidence has already garnered a massive user base of over 757,000 physicians, with over 40% of US physicians using the platform in their daily work17. Additionally, the platform’s credibility is indicated by its organic growth with over 95% of new users saying they heard about OpenEvidence from another physician18.
The Mount Sinai Partnership: A Landmark Enterprise Deployment
As healthcare AI experts have long argued, the winning strategy is to build products that don’t interrupt the clinician’s workflow and Open Evidence is ahead of that race. On March 31, 2026, Open Evidence announced their partnership with Mount Sinai Health System, one of the largest academic medical systems in the United States with seven hospitals. This collaboration marks the first enterprise-scale OpenEvidence deployment to extend access across the full clinical care team, including physicians, registered nurses, and pharmacists, broadening trusted, evidence-based clinical support beyond physicians alone to every professional involved in patient care20.
Healthcare AI does not fail only because the technology is flawed, it often fails because the technology cannot talk to the systems already in use. Hospital environments run on a patchwork of legacy platforms and EHR systems that rarely communicate seamlessly, each built on distinct data formats, protocols, and standards. Clinical data itself compounds the problem: it spans structured fields, free-text physician notes, imaging, and sensor data, none of which naturally fit into a single machine-readable format. Real-time data exchange, the backbone of any AI-assisted clinical decision, is precisely what legacy infrastructure struggles most to deliver21. Solving this requires more than a good AI model; it requires adoption of interoperability standards such as Fast Healthcare Interoperability Resources (FHIR), which enable structured, real-time data exchange across clinical systems. This is the technical wall that most health AI deployments quietly run into. The OpenEvidence and Mount Sinai partnership clears it by embedding directly into Epic, the dominant EHR platform in U.S. healthcare, rather than asking clinicians to work around it. Clinicians can now ask medical questions in natural language and receive answers grounded in peer-reviewed literature without ever leaving their existing workflow22.
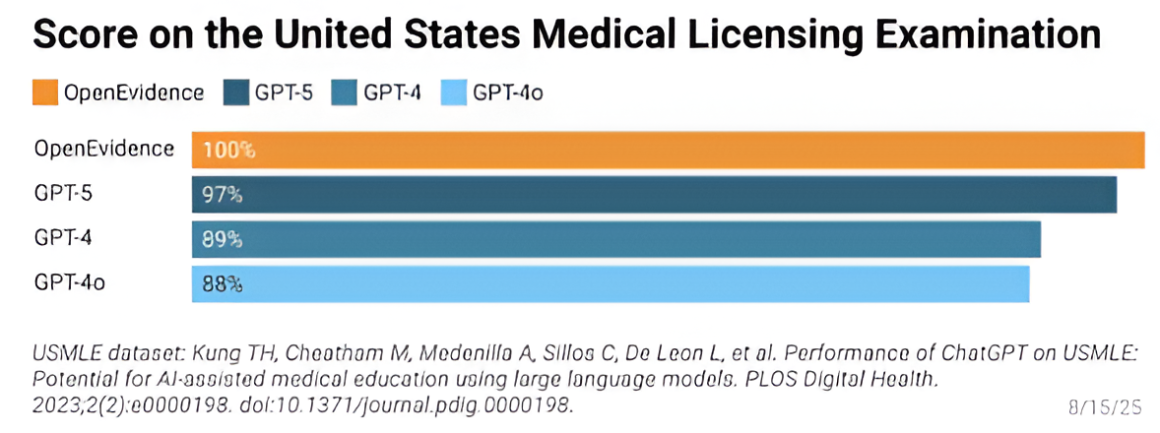
Behind the scenes, OpenEvidence’s LLM training and quality-check strategy is designed to keep pace with their scale. The system uses data from clinical trials, providers, past treatments, and insurance claims, with all information being reviewed before it is implemented. Any answers it provides are fully cited, drawing from peer-reviewed literature and guidelines. In August 2025, OpenEvidence’s AI model scored a perfect 100% on all three steps of the USMLE, compared to GPT-5’s score of 97%23.
However, one study by Jagarapu and colleagues found that when tested with complex scenarios from the MedXpertQA dataset, OpenEvidence only demonstrated approximately 41% accuracy26. While this is comparable to, if not better than, many clinical AI tools, it isn’t strong enough to be clinical-grade. Furthermore, since OpenEvidence is primarily trained on data from peer-reviewed journals, there is a possibility that potentially relevant information isn’t included because not all data is published. For example, about 50% of medical and health-related studies and 47% of clinical trial results are never published, which leads to publication bias27.
That same week, on April 2, 2026, OpenEvidence strategically partnered with Tandem to streamline evidence-based prescribing and prior authorizations, automating all the other patient visit steps in a patient visit28. This power duo allows clinical decision support and automation for some of the most tedious and time consuming treatment procedures for clinicians and their staff.
The Standard We Should All Be Measuring Against
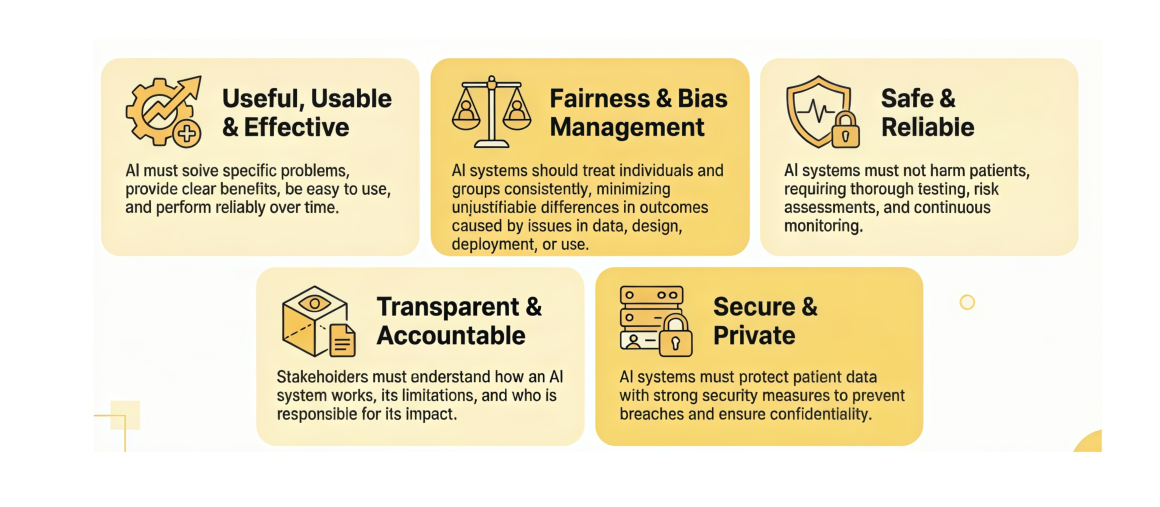
While no universal regulatory body has yet established a unified testing standard for health AI chatbots, a gap that remains one of the field’s most pressing challenges, the Coalition for Health AI (CHAI), a nonprofit representing leading health systems, AI companies, researchers, and patient advocates, has released a consensus-based Best Practice Guide for general health advice chatbots. Their mission is to advance the responsible development, deployment, and oversight of AI in healthcare by fostering collaboration across the health sector and their framework is organized around four responsible AI principles: usefulness and usability, fairness and bias management, safety and reliability, and transparency30. Key practices include grounding responses in authoritative and cited sources, building escalation logic for high-risk queries, conducting bias audits across demographic subgroups, and being transparent with users about what the AI can and cannot do29. Not every tool on the market meets these standards and CHAI has made no secret of that. Of the three LLMs mentioned here, OpenEvidence aligns most closely with CHAI’s framework for chatbots in healthcare: its model is trained exclusively on peer-reviewed literature, every answer is fully cited, access is limited to verified clinicians, and the company has pursued formal partnerships with major health institutions rather than open consumer deployment. ChatGPT Health and Claude are advancing rapidly, but the benchmark for responsible health AI already exists. CHAI’s playbook is not regulation, it is collective agreement among the best minds in the field about what responsibility looks like for every tool, from consumer facing chatbots to clinician facing clinical decision support. CHAI also publishes additional frameworks for clinical decision support, agentic AI, and other use cases on their website, chai.org30.
Somewhere between the benchmark scores, the subscription numbers, and the enterprise valuations, it is easy to lose sight of what this race is actually about. It is about the person who types their symptoms into a phone at 2 a.m. because they cannot afford an ER visit. It is about the clinician who has four minutes to make a decision and needs a better answer than their memory alone can provide. AI, built well, can serve both of them. Built carelessly, it fails both of them, sometimes catastrophically. The good news is that the checks and balances exist. The work now is simply to keep building the good, loudly and relentlessly, until it outweighs everything else this technology makes possible. That has always been how progress works. Healthcare just has less room for error than most. And this is what the AI race is really about, not which model wins, but whether we can shape the conditions around these systems fast enough because they are worthy of being trusted at scale.
About the Authors
Anisia Corona is a digital health entrepreneur and editor with 27 years of experience in healthcare. She is the founder of DxTx, a health tech company focused on strengthening the provider–patient relationship through AI-powered tools for physicians, such as clinical decision support for complex chronic conditions and conversational AI intake. Anisia also publishes a digital magazine that delivers proprietary and hard-to-find data and insights to clinicians. Anisia is the co-author of studies indexed by the National Institutes of Health and serves as a reviewer and on the Advisory Committee for NIH RECOVER research proposals and studies, as well as grant applications submitted to the United States Department of Defense. Anisia participates in working groups for the Coalition for Health AI (CHAI) as a Patient Advocate, approving best practices for the use of AI in healthcare. She also founded the Arizona Chapter of the AI Collective with a healthcare vertical, creating hands-on AI learning events that advance the use of AI in healthcare across Arizona.
Brenda Mao is an undergraduate student at the University of California, Berkeley, studying Molecular and Cell Biology and Economics. Her background is primarily in wet lab research (Wayne State University, Indiana University, Fudan University), but she has recently taken an interest in computational biology, the use of AI in healthcare, and healthcare policy. Besides interning at DxTx, Brenda is a strategy consultant for UC Berkeley’s Phoenix Consulting Group and an undergraduate researcher in the Drubin/Barnes Lab.
Jacqueline Vo is currently an undergraduate student at the University of California, Berkeley, majoring in Environmental Economics and Policy with minors in Data Science and Public Policy. She comes from a data analytics background as she has worked on a range of projects related to the environment, sustainable transportation and economics. Her current interests lie in analyzing data for anything policy-related in various fields concerning social welfare, such as healthcare, government policy and education. Being a DxTx intern has given her more insight into specific aspects of the healthcare sector such as patient-doctor relationships, expanding her breadth of knowledge and proving invaluable for policy analysis.
Rohan Melwani is an undergraduate student at the University of California, Berkeley, majoring in Neuroscience and Business Administration with a minor in Data Science. He has published research on neurodegenerative conditions and Long Covid and has industry experience as a life science consultant through UC Berkeley’s Healthcare Consulting Group and as an intern at DxTx, a startup building the next generation of AI-powered physician products. These experiences give Rohan a unique perspective on the intersection of healthcare, business, and technology in an industry being rapidly reshaped by AI.
Sources
- U.S. Department of War. “Trump Renames DoD to Department of War.” Department of War. 2025. https://www.war.gov/News/News-Stories/Article/Article/4295826/trump-renames-dod-to-department-of-war/
- Rock Health. “The Tortoise and the Hare of Care: Health AI Insights from Rock Health’s 2025 Consumer Adoption Survey.” Rock Health. 2025. https://rockhealth.com/insights/the-tortoise-and-the-hare-of-care-health-ai-insights-from-rock-healths-2025-consumer-adoption-survey
- b.well Connected Health. “OpenAI Selects b.well to Power Secure Health Data Connectivity for AI-Driven Health Experiences in ChatGPT.” b.well Connected Health. 2026. https://resources.icanbwell.com/openai-selects-bwell-to-power-secure-health-data-connectivity-for-ai-driven-health-experiences-in-chatgpt
- ARISE AI. “Medical AI Superintelligence Test (MAST) Benchmark.” ARISE AI. 2026. https://bench.arise-ai.org
- Walser, T., et al. “Evaluation of ChatGPT Health Triage Performance Using Clinician-Authored Vignettes.” Nature Medicine. 2026. https://www.nature.com/articles/s41591-026-04297-7
- Nature Medicine Supplemental Data. “Triage Accuracy by Clinical Domain — Supplemental Materials.” Nature Medicine. 2026. https://static-content.springer.com/esm/art%3A10.1038%2Fs41591-026-04297-7/MediaObjects/41591_2026_4297_MOESM1_ESM.pdf
- Coldewey, Devin. “ChatGPT Uninstalls Surged by 295% After DoD Deal.” TechCrunch. March 2, 2026. https://techcrunch.com/2026/03/02/chatgpt-uninstalls-surged-by-295-after-dod-deal/
- Yahoo Finance. “ChatGPT Uninstalls Surged 295% After DoD Deal.” Yahoo Finance. 2026. https://finance.yahoo.com/news/chatgpt-uninstalls-surged-295-dod-000337143.html; GoodAI. “OpenAI Acquired OpenClaw — Why Workflow Matters.” GoodAI Substack. 2026. https://goodai.substack.com/p/openai-acquired-openclaw-why-workflow
- Anthropic Support. “Import and Export Your Memory From Claude.” Anthropic. 2026. https://support.claude.com/en/articles/12123587-import-and-export-your-memory-from-claude
- eMarketer. “Anthropic Debuts Claude for Healthcare as Competition Heats Up in Medical AI Sector.” eMarketer. 2026. https://www.emarketer.com/content/anthropic-debuts-claude-healthcare-competition-heats-up-medical-ai-sector
- Sipher, Joe. “I Tested Amazon’s Health AI. It Failed.” LinkedIn. April 2, 2026. https://www.linkedin.com/posts/joesipher_i-tested-amazons-health-ai-it-failed-activity-7445492746678800384-huFR
- Fierce Healthcare. “JPM26: Anthropic Launches Claude for Healthcare, Targeting Health Systems, Payers.” Fierce Healthcare. January 2026. https://www.fiercehealthcare.com/ai-and-machine-learning/jpm26-anthropic-launches-claude-healthcare-targeting-health-systems-payers
- Modern Healthcare. “Banner Health, Anthropic Partnership: AI in Healthcare.” Modern Healthcare. 2025. https://www.modernhealthcare.com/health-tech/ai/mh-banner-health-anthropic-partnership-ai/
- Clinical AI Report. “OpenEvidence Review.” Clinical AI Report. 2026. https://clinicalaireport.com/reviews/open-evidence
- OpenEvidence. “Wiley and OpenEvidence Partner to Deliver Trusted Research to Physicians at the Point of Care.” OpenEvidence. 2026. https://www.openevidence.com/announcements/wiley-and-openevidence-partner-to-deliver-trusted-research-to-physicians-at-the-point-of-care
- OpenEvidence. OpenEvidence Corporate Website. 2026. https://www.openevidence.com
- Farr, Christina. “OpenEvidence, ChatGPT for Doctors, Doubles Valuation to $12 Billion.” CNBC. Jan. 21, 2026. https://www.cnbc.com/2026/01/21/openevidence-chatgpt-for-doctors-doubles-valuation-to-12-billion.html
- Contrary Research. “OpenEvidence Company Profile.” Contrary Research. 2026. https://research.contrary.com/company/openevidence
- Yahoo Finance. “OpenEvidence Achieves $1 Billion Valuation.” Yahoo Finance. 2025. https://finance.yahoo.com/news/openevidence-achieves-1-billion-valuation-031600643.html
- OpenEvidence. “OpenEvidence Creates the First AI in History to Score a Perfect 100% on the USMLE.” OpenEvidence. 2025. https://www.openevidence.com/announcements/openevidence-creates-the-first-ai-in-history-to-score-a-perfect-100percent-on-the-united-states-medical-licensing-examination-usmle
- GlobeNewswire. “Mount Sinai Health System Collaborates with OpenEvidence to Provide Evidence-Based Knowledge Within Electronic Medical Record.” GlobeNewswire. March 31, 2026. https://www.globenewswire.com/news-release/2026/03/31/3265707/0/en/Mount-Sinai-Health-System-Collaborates-with-OpenEvidence-to-Provide-Evidence-Based-Knowledge-Within-Electronic-Medical-Record.html
- Lim, et al. “Integration Barriers for Artificial Intelligence in Clinical Workflows.” PMC/National Center for Biotechnology Information. 2025. https://pmc.ncbi.nlm.nih.gov/articles/PMC12700513/
- Mount Sinai Newsroom. “Mount Sinai Health System Collaborates with OpenEvidence to Provide Evidence-Based Knowledge Within Electronic Medical Record.” Mount Sinai. 2026. https://www.mountsinai.org/about/newsroom/2026/mount-sinai-health-system-collaborates-with-openevidence-to-provide-evidence-based-knowledge-within-electronic-medical-record
- Fierce Healthcare. “OpenEvidence AI Scores 100% on USMLE; Company Offers Free Explanation Model.” Fierce Healthcare. August 2025. https://www.fiercehealthcare.com/ai-and-machine-learning/openevidence-ai-scores-100-usmle-company-offers-free-explanation-model
- Kim, Min Jae, et al. “Assessing Large Language Model Performance on USMLE Step 1.” PubMed/NCBI. 2024. https://pubmed.ncbi.nlm.nih.gov/39558670/
- Authors. “Comparative Performance of Claude, ChatGPT-4, and Gemini on Polish Medical Licensing Examinations.” Nature Scientific Reports. 2025. https://www.nature.com/articles/s41598-025-17030-0
- Jagarapu, Arun, et al. “Evaluating AI Tool Performance on Complex Clinical Scenarios Using MedXpertQA.” medRxiv. 2025. https://www.medrxiv.org/content/10.64898/2025.11.29.25341091v1.full
- TranspariMed. “Cochrane Review: 47% of All Clinical Trial Results Are Not Made Public.” TranspariMed. 2020. https://www.transparimed.org/single-post/cochrane-review-47-of-all-clinical-trial-results-are-not-made-public; Dwan, K., et al. “Systematic Review of the Empirical Evidence of Study Publication Bias.” PMC/NCBI. 2014. https://pmc.ncbi.nlm.nih.gov/articles/PMC4198242/
- OpenEvidence. “OpenEvidence and Tandem Partner to Streamline Evidence-Based Prescribing and Prior Authorizations.” OpenEvidence. April 2, 2026. https://www.openevidence.com/announcements/openevidence-and-tandem-partner-to-streamline-evidence-based-prescribing-and-prior-authorizations
- Coalition for Health AI (CHAI). “General Health Advice AI Chatbot: Use Case Best Practice Guide.” CHAI. 2025. https://www.chai.org/workgroup/use-case/general-health-advice-ai-chatbot
- Coalition for Health AI (CHAI). CHAI Homepage and Mission. CHAI. 2026. https://www.chai.org/
Anisia Corona is a digital health entrepreneur and editor with 27 years of experience in healthcare. She is the founder of DxTx, a health tech company focused on strengthening the provider–patient relationship through AI-powered tools for physicians, such as clinical decision support for complex chronic conditions and conversational AI intake. Anisia also publishes a digital magazine that delivers proprietary and hard-to-find data and insights to clinicians. Anisia is the co-author of studies indexed by the National Institutes of Health and serves as a reviewer and on the Advisory Committee for NIH RECOVER research proposals and studies, as well as grant applications submitted to the United States Department of Defense. Anisia participates in working groups for the Coalition for Health AI (CHAI) as a Patient Advocate, approving best practices for the use of AI in healthcare. She also founded the Arizona Chapter of the AI Collective with a healthcare vertical, creating hands-on AI learning events that advance the use of AI in healthcare across Arizona.




